
Martin Roest
November 29, 2018
Martin Roest
November 29, 2018
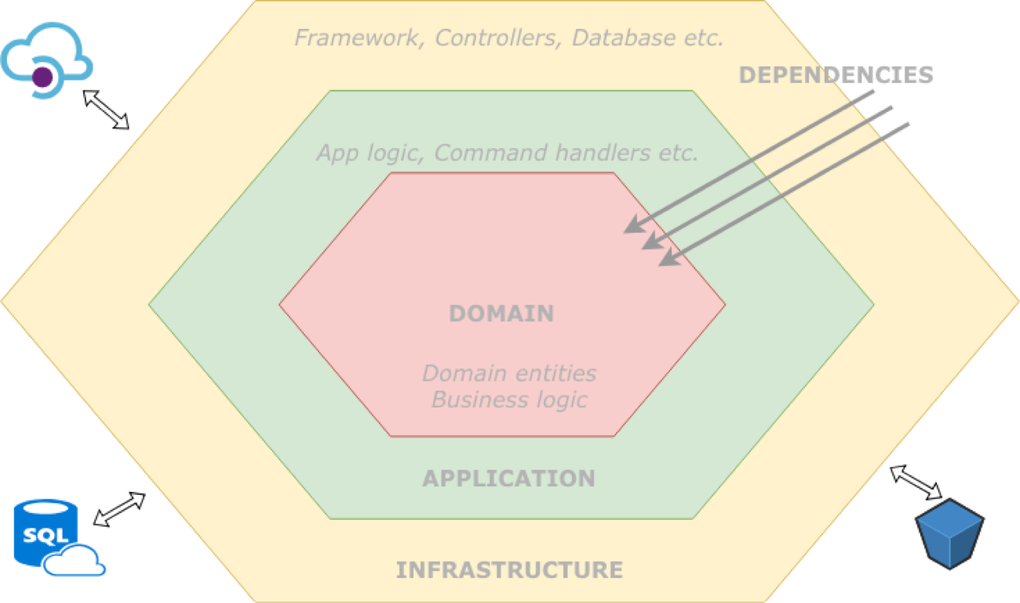
As a software engineer that mostly practices object oriented programming (OOP) I value principles like SOLID. When architecting apps I prefer a layered approach. I have typical layers like Application, Domain and Infrastructure. This helps me separate concerns and build a maintainable codebase. With this post I want to share how I try to create loosely coupled and maintainable software.
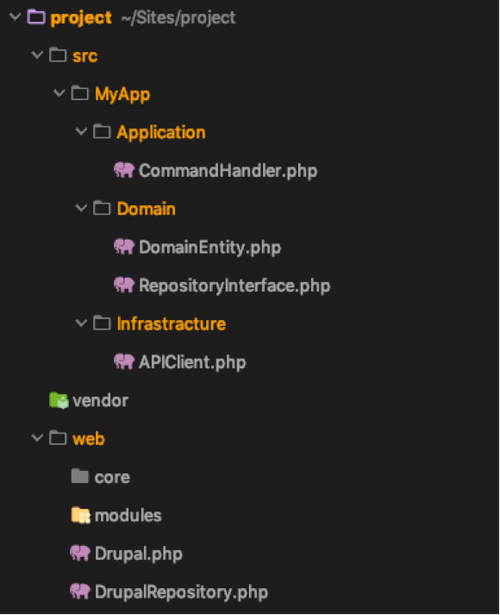
I usually have a repository layout that reflects the layers. Meaning that I have the folders Application, Domain and Infrastructure. Although I have some exceptions for the infrastructure layer. I consider everything that interacts with the “outside”, infrastructure. Which means that the presentation layer is also infrastructure. Since those responsibilities are, in my case, usually handled by the framework. Depending on the framework, the code I write to extend the framework may not always be in the infrastructure folder. Key in layered architecture is to respect the layer boundaries and have good separation between the layers. Still you should be able to interact between the layers. Managing your dependencies across the layers become very important.
When working with a CMS like Drupal I also apply the layered approach. Obviously that has some impact on the repository layout. The Drupal codebase is infrastructure but due to the Drupal folder layout it’s not in my infrastructure folder.
The dependency inversion principle (DIP) enables the separation of the layers. It states that high-level modules should not depend on low-level modules. Infrastructure like your framework is considered a low-level module that interacts with the “outside” and therefore an “outer” layer. Domain is high-level module and an inner layer. Which means that your domain layer should not depend on your framework layer. Which will result in dependencies only going in one direction.
Let me give an example that demonstrates the separation. For example you have a domain entity that you want to persist as a Drupal entity in order to use Drupal’s theming/presentation layer to display it. So how do you save the domain entity without creating a dependency in the domain layer on your infrastructure (Drupal). The repository pattern will help you solve this. Not to confuse this with the “repository” layout I’ve mentioned before. The repository refers to a collection of entities. The repository is responsible for persisting the domain entity. By creating an interface for the repository in the domain layer, the domain code can “work” with the repository without worrying how to actually persist the entity. Your code in the domain layer now depends on the abstraction of the repository. The implementation of the repository interface is created as part of a custom Drupal module. In the Drupal module you create a repository object that, with the help of the framework, can save the Drupal entity.
Unfortunately the layers create a bit of extra complexity. Since the repository implementation saves Drupal entities you have to map your domain entity into a Drupal entity. This can be done by creating a mapper object. Inject the mapper in the repository. Once you call the repository->persist(DomainEntity) the repository can map the domain entity to a Drupal entity before saving it to the database. Since the mapper is a direct dependency of the repository it belongs to the infrastructure and the domain layer has no knowledge of it.
Now that you’ve separated the layers by creating an interface you still need to wire the objects with real implementations. Use your framework’s DI / Service container to do this. Most frameworks like Symfony, Laravel, Drupal have this available. Simply create services and inject those in your objects. The result is a loosely coupled codebase. Since your domain is agnostic to the infrastructure it makes testing your domain much easier. With tools like PHPUnit and Behat you can now test your domain code without your infrastructure. Simply replace the infrastructure by creating Fake or Stub testdoubles based on the interfaces in the domain to remove the dependency of having a real database or remote API when testing.
Once projects grow bigger you may end up with lots of interfaces/dependencies. As with a proper layered architecture that follows the dependency inversion principle, dependencies can only go one direction. Again, your domain layer should not depend on the infrastructure layer (only on abstractions). To enforce those rules I use Deptrac. Deptrac is a static code analysis tool that helps enforcing dependency rules between layers. You can define the layers of the app based on namespace or folder location. So if you follow a repository layout like discussed you can easily define the layers in Deptrac. Once you run deptrac it will report violations of the rules you define.
Deptrac example output:
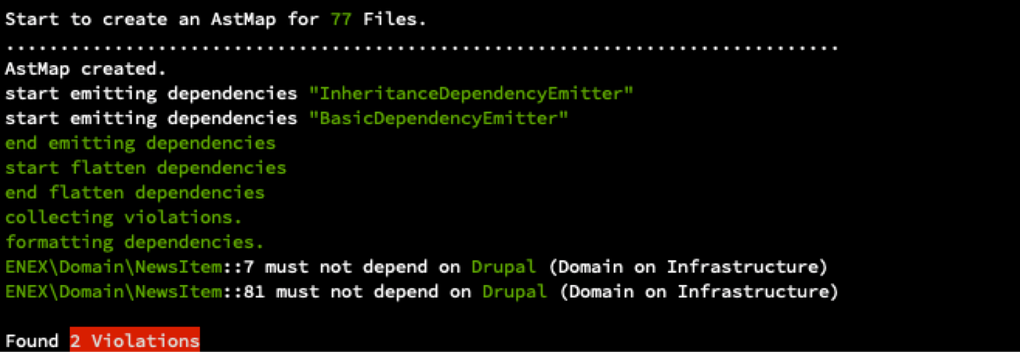
We run Deptrac on our CI/CD pipeline in a early stage. If you fail to comply with the rules, CI will report a broken build. Especially when apps get bigger it’s very helpful to automatically verify your dependency rules.
If you know DDD you’re probably familiar with the concepts discussed here. Many of them are highly influenced by DDD. Following a layered approach and properly apply DIP you actually have a Ports and Adapters or Hexagonal architecture approach. I find that these patterns and principles help me create maintainable software. It comes with a bit of extra complexity to properly separate the layers, but it’s well worth the investment. Obviously like all patterns there is an anti-pattern. Be aware of the “Sinkhole” anti-pattern. If all of your requests just flows through the different layers without any logic, layered architecture may be not the best approach. Or at least minimize the number of layers to control the complexity overhead. Since the layered approach is pretty much the same for every app it enables developers to have consistent architecture setup across projects. Due to the separations and abstractions, testing the individual layers is much easier. This will result in a maintainable codebase.
Thank you for reading this post. I’d like to learn about your experiences as well! Please contact me and share your experience, questions or feedback.