
Boy Baukema
November 6, 2015
Boy Baukema
November 6, 2015
Last year we switched to using Slack for all our internal communication and it’s working out nicely. It’s very developer centric in that it offers integrations with lots of services like Travis CI, GitHub, etc.
When we started using Slack one of our developers was sending a file, had his Developer console open and noticed that even though he’d not chosen to share the file public, the API gave back a public URL anyway. Much to his dismay when he tried it out in a new private browsing window he could download his file without authentication!
Everything you share on Slack automatically becomes available on a public url.
Concerned with the security of our communications (we don’t share financials or credentials through Slack fortunately, but we may share company or customer sensitive information) I decided to look into it and make it a teachable moment on ‘secret URLs’.
I shot some video at a bachelor party that I shared to the participants, a lot of whom I didn’t particularly know, as YouTubes ‘Unlisted videos’. All they needed was the URL and they could watch the videos, but that URL was not published anywhere.
And I shared a PDF with some work to a mailinglist via Dropboxes ‘Share Link’ functionality.
All they needed for access was the URL.
As a user I love secret URLs. They give me some wiggle room between “completely private / protected” and “completely public”. Some content isn’t exactly secret but doesn’t deserve to be published and communicated to the world at large. They bear some resemblance to the physical act of handing out a document in a meeting or photos at a party. The only way to gain access is to be granted so by someone who has been granted access before, forming a trust chain.
However, unlike in the ‘real world’, what is shared is not something physical, but information. And information wants to be free. It is (in some cases frighteningly) easy and fast to share information these days.
Intended or unintended (think of browser plugins, HTTP caching proxies or well intentioned friends and colleagues) these secret URLs can become not so secret.
And even if the link no longer works, that doesn’t mean the content has not been copied.
Now if you were to implement secret urls, your second line of defence would be to empower the user by giving her the ability to revoke a public link, explicitly in the UI (as Slack appears to do, more on that later) and / or implicitly by letting the user choose how long to share the link for.
But the first line of defence is to let the user choose whether or not something should actually be public. And users should be informed that secret URLs should only be used for semi-public information.
Putting aside the likelihood that a URL is leaked through some means, having public URLs opens up the possibility for brute forcing. Now the question “How easy is it to brute force a secret URL?” is actually quite interesting and the answer has changed a bit recently.
Brute forcing depends on trying many combinations as fast as possible and is usually done on a local data set. This is mostly because of latency.
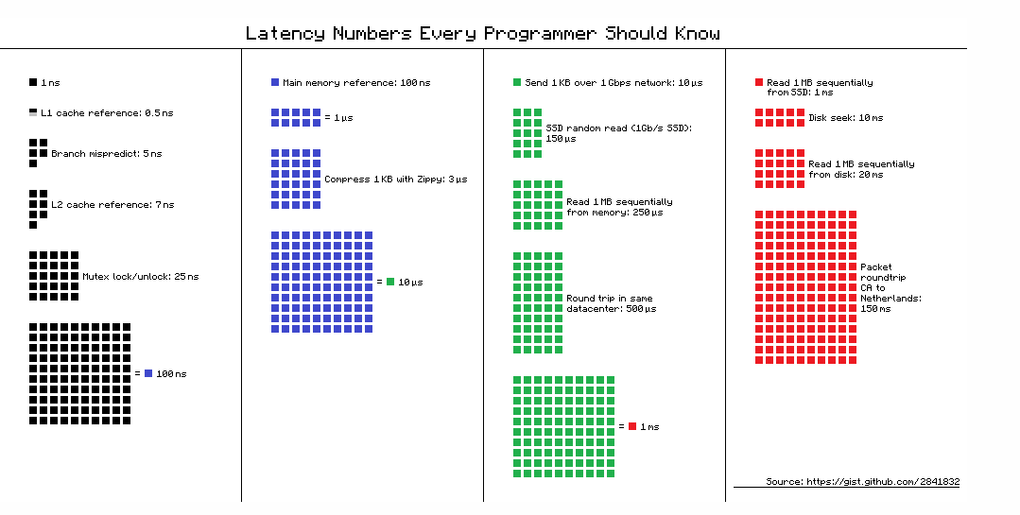
Going over a network is simply several orders of magnitude slower than trying a combination locally. The further you are from the target data, the more time is required to try a combination.
Fortunately for the brute forcer the advent of ’the cloud’ has ensured two things:
A wholly unscientific benchmarking of default 404s against a small Digital Ocean LAMP VM produces the following ‘Request per second’ (rps) numbers:
Brute forcing over the network does introduce some additional bottlenecks:
It also introduces the possibility to be detected or stopped by generating too much load on the target.
Ironically the better tuned and configured the target is, the easier it is to brute force them.
At 1400 rps a space of 16 million combinations (6 character hexadecimal) is checked in 3 hours.
At 15 rps it will take 12 days.
8, same as passwords, duh.
If only it was so easy. Deciding how many characters you need depends on:
Here is a gist with JavaScript code that can help you decide: brute-force-chances.js.
However, as a default I would state that:
A token of 8 alphanumeric upper and lower case truly cryptographically random characters should be able to withstand Twitter like brute forcing load for a year.
Note that they must be cryptographically random (for instance by using the excellent Zend\Math\Random library in PHP) any ordering (like with using timestamps) would defeat the purpose.
Well… brute focing in theory then. Understandably Slack forbids automated testing:
Please only test with your own team when investigating bugs. Automated testing is not permitted.
- https://slack.com/whitehat
However with what we’ve seen and the JavaScript gist should be enough to prove the feasibility.
First let’s upload a file. In my own Slack Team (relaxnow.slack.com) I uploaded a file which made the Slack client do a request to /files.info that gives back some JSON data including the following:
First off we clearly see is_public: false, but a (working) URL for permalink_public.
Next we see a lot of locations that the file (or copies of it) are hosted on. And most of them actually include the filename, which is against OWASP recommendations and potentially introduces vulnerabilities.
Then again, it does help against brute force attacks, which are made significantly harder when in combination with a random file id.
However when we look at the public links we see a public permalink without file name in the following form:
https://slack-files.com/T02EMLM07-F02GJ6FPC-a9d3f2
Trying out a couple of uploads in quick succession (which Slack makes very easy with drag and drop) gives the following public permalinks:
https://slack-files.com/T02EMLM07-F02GHGJ8H-5d8bbf https://slack-files.com/T02EMLM07-F02GJCMF0-ee919f https://slack-files.com/T02EMLM07-F02GJCN0Q-c6e078 https://slack-files.com/T02EMLM07-F02GHGKNH-f15619 https://slack-files.com/T02EMLM07-F02GHGL9V-9c6a0a https://slack-files.com/T02EMLM07-F02GJCPMA-8bbfb6
Which looks to be in the following format:
Seems secure enough on the surface, but let’s look closer.
https://slack-files.com/T02EMLM07-F02GJ6FPC-a9d3f2
Very helpfully Slack includes the Team ID in the HTML output if you go to the log in page for a team:
var team\_id = 'T02EMLM07'; var email\_regex = new RegExp("\[a-z0-9!#$%&'\*+/=?^\_\`{|}~-\]+(?:\\\\.\[a-z0-9!#$%&'\*+/=?^\_\`{|}~-\]+)\*@(?:\[a-z0-9\](?:\[a-z0-9-\]\*\[a-z0-9\])?\\\\.)+\[a-z0-9\](?:\[a-z0-9-\]\*\[a-z0-9\])?", 'i');
One down, two to go.
https://slack-files.com/T02EMLM07-F02GJ6FPC-a9d3f2
Fortunately for an attacker Slack helped by giving a different 404 when a file exists for the Team but the Token is invalid:
- https://slack-files.com/T02EMLM07-F02GJ6FPC-aaaaaa
Than it does when a File ID is invalid:
- https://slack-files.com/T02EMLM07-F02AAAAAA-a9d3f2
Next let’s look at the base36 numbers of the files uploaded in quick succession:
GHGJ8H GJCMF0 GJCN0Q GHGKNH GHGL9V GJCPMA
Or converted to base 10 and minus 990,000,000:
6783713
9960444
9961226
6785549
6786355
9964594
It seems that the numbers are sequential, perhaps for two file servers. Testing with another Slack instance reveals that this number is not bound to a Team. Likely this is the number of files uploaded.
While 36 to the 6th is still a significantly high number (35 days at 700 RPS), in 2014 already 55% could be discarded because it is sequential (< 17 days at 700 RPS for a single file).
However you can discard far more if you’re only interested in recent files.
Slack is very helpful here as it returns the time that the file was uploaded in the If-Modified-Since allowing you to use public links to correlate File IDs to a time.
https://slack-files.com/T02EMLM07-F02GJ6FPC-a9d3f2
The token was a 6 character hexadecimal, most likely a hash of some data. I could not find a correlation to file name or some other piece of data that an attacker might know.
When ‘revoking’ a public file in the UI, this token gets renewed.
However a > 50% chance of guessing this token can be achieved with 700 RPS in less than 7 hours. If you have the time and go at a less noticable 70 RPS it will take approximately 2 days to get the same chance.
Slack had taken a weak approach to securing private files. Combining this with the decision to make all files public lead to a rather large attack area that could be exploited by a dedicated attacker.
In fact for known file-sharing services these types of attacks are already happening.
While it took some time, Slack has made the following changes to fix this vulnerability:
Making it impractical to try brute forcing… for Slack that is :-).
Security StackExchange: Are random URLs a safe way to protect profile photos?
Exposing the Lack of Privacy in File Hosting Services [PDF]
I had heard that Slack was terrible with it’s bug bounty program, but this took over a year. Often with little to no response from Slack. I will certainly think twice about working with them in the future.
Julyish 2014 - My colleague initially disclosed this via a short blurb on the Slacks bug bounty program with HackerOne. Slack closed this as ‘Not a bug’.
August 27th 2014 - This prompted Private files are public and brute forcable"
September 2nd 2014 - Response from :
To address the points individually:
September 3rd 2014 -
Thanks for the feedback!
Rate limiting based on IP would mitigate this, but is fraught with gotchas:
would be undone if you would need to ever support IPv6.
opens up another vector for attack. I can deny YOU access to files by tricking you into visiting a special page that spams slack-files.com
people behind proxies (carrier grade NAT is becoming a thing with IPv4 depletion, though just normal work or college proxies are more common) would suffer from 1 bad apple.
I would just advise some form of periodic monitoring coupled with stronger tokens.
I would make that more visible in the UI. Just remove the whole ‘is_public’ bit and let it show that (for now at least) there is always a public URL and users can ‘refresh’ it.
Yes, simple fix would be to make the token 8 character alphanumeric. That alone would be enough to make the attack no longer feasible.
Thanks for keeping me up to date, I’d love to publicise the post with the changes that were made!
October 8th 2014 - , no response.
January 13th 2015 - , no response.
January 28th 2015 -
February 16h 2015 -
March 2nd 2015 - Response from :
We apologize for the delayed reply. We track these issues via our internal bug system, and only reply to the reporter once the bug is resolved internally. We generally ignore messages asking for updates, as we receive a high volume of these (even for non-issues).
Here is the update:
This was partially resolved in December by increasing the length of the secret to 10 characters. Unfortunately, this is not one issue, as it requires updates to more than just the secret length. We are still working to resolve all affected apps before considering this issue closed.
March 2nd 2015 - :
Thank you for the update! Though it’s disheartening to know that you won’t even get this reply, I’ve certainly seen enough of the crap you guys get through hackerone to understand not paying too close attention.
Just checked and the last bit appears to be 10 character random alphanum. This would be enough to make brute force impossible.
I can understand wanting to get rid of the ‘public-by-default’ first but I have put a significant amount of time into the blog post and do want to see that published before we switch to another blog engine and I have to redo the entire thing.
As it stands, though please correct me if I’m wrong, your users are not in any danger by posting and I’ve followed the Guidelines to the letter.
I’ll post when I have time to update my blog with this correspondence.
March 10th 2015 - Response from :
There are still changes to this system that we prefer to make before disclosure. If you have already disclosed, that is fine, but if not, please wait until we have fully resolved the issue.
September 28th 2015 -
October 2nd 2015 - Response from :
Thanks for your patience on this issue. I’ll be in touch soon with a more detailed update about the changes we’ve made.
October 30th 2015 - :
It has been over a year.
Maybe if you give me a date (in 2015!) I can postpone publishing until then.
November 3rd 2015 - awards $500,- bounty
November 3rd 2015 - :
Hi Boy,
Thanks for your patience on this issue. As you recommended, we’ve increased the entropy on the tokens. We’re also continuously working on monitoring for brute-force attacks across our service.
Cheers, and happy bug hunting!
-Leigh
November 4th 2015 -
November 6th 2015 -
You read it all! Sorry for the length. Hope you liked it and learned something! If you liked this post you may also like:
To find out more about Ibuildings and security see also: Security expertise at Ibuildings.